Written by JS970
on
on
Types
Concept of Type
- Type은 어떤 프로그래밍 언어의 좋고 나쁨을 가리는 척도가 될 수 있다.
Scalar(단순) vs Composite(복합)
Scalar타입은 atomic values를 나타낸다.Composite타입은 atomic타입을 unit으로 가지는 타입이다.
Primitive(기본) vs User-defined(사용자 정의)
Primitive타입은 language에서 지원하는 타입이다.User-defined타입은 사용자에 의해 새롭게 정의된 타입이다.
Fundamental(기초) vs Derived(유도, Compound)
Fundamental타입은 그 자체로 정의되는 타입이다.Derived타입은Compound타입이라고도 하며,Fundamental타입 또는Derived타입을 이용하여 정의된다.- integer 변수의 경우
Fundamental타입이다.- 정수형 변수는 그 자체로 정의된다.
- 포인터 변수의 경우
Compound타입이다.int *는int라는Fundamental타입에 의해 정의된다.int **는int *라는Compound타입에 의해 정의된다.int *a[]는int *라는Compund타입에 의해 정의된다.
Compound타입은 타입 구조가 생성되며, 트리로 표현 가능하다.int *,int **,int *a[]의 트리를 나타내면 아래와 같다.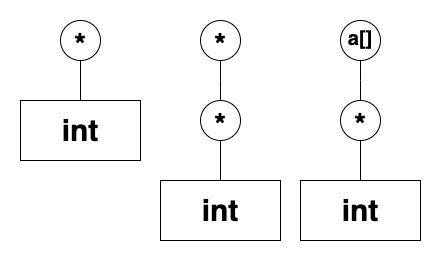
분류 예시
pointer타입의 경우Compound타입이지만Composite타입은 아니다.enum타입 역시Compound타입이지만Composite타입은 아니다.
Primitive Types
Primitive데이터 타입은 다른 타입으로 정의되지 않는 타입을 의미한다.- 일반적으로 하드웨어에 의해 지원된다.(그렇지 않은 경우도 있다.)
Integer
integer타입은 일반적으로 하드웨어를 반영하여 정의된다.integer타입의 크기는 하드웨어의 버스 사이즈를 word로 하여 정의된다.- byte, word, long word, quad word등
- 일반적으로
2's complement를 사용하여 정수를 표기한다.- 정수를 표기하는 방법은 크게
Sign-Magnitude,1's complement,2's complement가 있다. Sign-Magnitude는 부호 비트를 설정하여 표기하는 방법으로, 덧셈 연산에서 직관성이 떨어진다. 또한 0을 표기하는 방법이 2개 존재한다는 문제점이 있다.1's complement는 이진수의 1의 보수 형태로 0과 1을 반전시켜 연산하는 방법이다. 덧셈 연산은 직관적이지만 여전히 0을 표기하는 방법이 2개 존재한다.2's complement는 1의 보수 표기에 1을 더한 값이다. 덧셈 연산은 직관적이며 unique zero를 가진다.
- 정수를 표기하는 방법은 크게
2's complemtnt가 일반적인integer타입을 표기하는 방법이라고는 하지만, 항상 그런 것은 아니다. 이는 구현의 영역(언어 설계)이므로 임의로 추측해서는 안된다.
Floating Point
- 실수를 의미하지는 않는다. 실수의 근사값을 표기하는 방법이다.
- IEEE754표준을 따른다.
- 1비트의 signed bit, 8(or 11)비트의 exponent(지수부)비트, 23(or 52)비트의 fraction(mentisa, 가수부)비트를 통해 32(or 64)비트 환경에서 실수의 근사값을 표기한다.
Others
Decimal- business application에서 사용된다.
- 10진수 형태로 구성된다.
- 1282를 표현하기 위해선 한 자리당 4비트가 필요하므로 총 16비트가 필요하다.
- 제한된 범위 내에서 정확성을 보장한다는 장점이 있다.
- 하지만 범위가 제한되며, 메모리를 낭비한다는 단점이 있다.
Boolean- bit로 구현할 수 있지만 보통은 byte로 구성한다.
- readability를 상승시킨다.
Character- ASCII : 7bit를 사용하여 알파벳 계열 문자를 ㅍ현한다.
- Unicode : 16bit를 사용하여 international character를 표현할 수 있다.
Character String
Design issues
- 배열의 일종으로 볼 수도 있고(C), primitive type으로 볼 수도 있다(C++).
- c의 경우 String은 Character String이므로, 길이를 구하기 위해 배열을 순회해야 한다.
- str.length()가 for 문 안에서 사용되었다면 nested loop이므로 O(n)이 아닐 수 있음에 유의
- 이 때문에 가장 앞 비트에 크기를 저장하는 인코딩을 사용하기도 한다.
- 길이가 가변적인지, 고정적인지 생각해야 한다.
FORTRAN,Ada,COBOL은 static length를 가진다.C,C++,PL/I은 limited dynamic하게 배열의 크기를 가진다.SNOBOL4의 경우 dynamic한 배열의 크기를 가진다.- static length는 dynamic length방식에 비해 inexpensive하게 사용할 수 있다. 따라서 상황을 고려하여 dynamic length을 지원해야 할 가지가 있는지 생각해 봐야 한다.
String Operations
- assignment : 대입 연산
- comparison : 비교 연산
- concatenation : string합치기
- sub-string reference : sub-string 참조
- pattern matching : 패턴 매칭
Implementation of string

- static length를 가지도록 구현한다면 compile time descriptor로 충분히 구현 가능하다.
- limited dynamic length로 구현한다면 run-time descriptor를 필요로 할 수 있다.
- C언어의 경우 string타입을 위한 run-time descriptor를 가지지는 않는다.
- dynamic length로 구현할 결우 run-time descriptor가 필요하다.
- allocation, deallocation비용이 발생한다.
User-Defined Ordinal Types
Ordinal Type
- 0또는 양의 정수를 포함하는 범위의 집합
- 서수(순서)로 사용된다.
integer,character,boolean은 Ordinal Type이다.
Cardinal Type
- 기수(값, 양)로 사용된다.
User-Defined Ordinal Type
- Enumeration Type
- Enum 내부에서 정의된 값을 가지므로
Compound타입이다. - 하지만 atomic value를 가지므로
Composit타입은 아니다.
- Enum 내부에서 정의된 값을 가지므로
- Subrange Type
- ordinal type이 연속적으로 정렬된 것
- 아래는 Pascal예시이다.
type index = 1..100;
- 아래는 Pascal예시이다.
readablilty,reliability의 관점에서 pros가 있다.realiability의 경우 범위를 초과했을 경우 컴파일 타임의 검사가 가능하다.
- ordinal type이 연속적으로 정렬된 것
Array
Composit타입이다.- indexing을 통해서 원소에 접근한다.
Design issues
- Subscript Type & range checking
FORTRAN,C는 integer만 subscript type으로 허용한다.Pascal,Ada는 어떤 ordinal type이든 허용한다.
- The Maximum Number of Subscripts
C,C++은 1차원 배열 접근을 지원한다. 즉, A[i][j] 같은 방식으로 다차원 배열을 구현한다.BASIC,FORTRAN의 경우 A[i, j]와 같은 다차원 배열 접근을 지원한다.
Array Categories
- Static
- subscript의 범위 및 storage binding이 static이다.
FORTRAN에서 이런 방법을 사용한다.
- Fixed Stack-dynamic
- Stack-dynamic
- Heap-dynamic
java에서 이런 방법을 사용한다.
Conformant Array
Open Array와 상반되는 개념이다.BASIC,Pascal에서는 index range가 type의 일부였다. 아래의 두 배열은 서로 다른 타입이다.
VAR
MyArray1 : ARRAY [1..10] OF INTEGER;
MyArray2 : ARRAY [1..20] OF INTEGER;
- 이에 불편함을 느껴 Conformant array의 개념이 등장하였다.
- 아래의
C코드에서 두 배열은 서로 같은 타입이다.
- 아래의
int MyArray1[10];
int MyArray2[20];
- 처음 살펴봤던
Pascal에서도 ISO Standard에 따른 Conformant array를 지원한다. - 아래는
Pascal의 conformant array이다.
PROCEDURE MyProc(VAR x : ARRAY [low..high : INTEGER] OF INTEGER);
Open Array
- ISO 표준은
conformant array이지만, 표준이 재정되기 전에 배열의 index range를 전달하기 위한 방법으로 사용되었다. - lower bound 에 대한 정보는 알 수 없다.
- upper bound에 대한 정보는 High라는 함수를 사용하여 얻을 수 있었다.
C,C++의 배열 역시 open array의 일종으로 볼 수 있다.java의 배열도 유사하나java의 배열은 객체이다.
Array Operations
- 배열 연산자는 배열을 unit으로 동작한다.
- 전체 배열이 연산의 피연산자가 된다.
- FORTRAN 90
- element wise array operations 지원
- Intrinsic functions for array operators
- matrix multiplication
- matrix transpose
- vector dot product
- slice
- row slice, column slice
- Ada
- single dimension array에서 연속된 원소들에 대한 slice지원
- string에 대한 slice(substring reference)지원
Implementation of Arrays
- Compile Time Descriptor
- array descriptor를 사용한다.
- descriptor는 lower bound, upper bound등 배열에 대한 정보를 가진 벡터이다.
- 이를
dope vecotor라고 부른다. 검사용 벡터라는 뜻이다.
- 첨자(index)를 통해 주소(address)에 접근하는(mapping) access function을 가진다.
- 이때 언어에 따라 row major, column major 구현 방법이 나뉜다.
- 사실 대부분의 언어는 행우선으로 구현된다.
- FORTRAN은 Array를 열우선으로 구현한 대표적인 언어이다.
- C언어 예시
int a[2][3] = { {1, 2, 3}, {4, 5, 6}, {7, 8, 9}};- C언어는 대표적인 행우선(row major) 언어이다.
- a[0] = {1, 2, 3}이므로 a[0][0], a[0][1], a[0][2]는 차례대로 1, 2, 3이다.
- 이처럼 열을 우선적으로 순회한다.
- 열우선의 경우 아래와 같이 구현한다.
location(matrix[i,j]) = (address of matrix[1, 1]) + ((i-1)*n + (j-1)) * (element size) = A + B*i + C*j
Associative Array
- 데이터 원소들(elements)의 정렬되지 않은 집합(collection)이다.
- 데이터 원소들(elements)은
key에 의해 indexing된다. - 이때 element와 key는 hashing function을 통해 매핑된다.
Reference
Stack Overflow - What is a Conformant Array?
Record
- Array는 homogenous aggregation이며 index를 통해 원소에 접근한다.
- 반면 Record는 heterogenous aggregation이며 name을 통해 원소에 접근한다.
Record Operation
- Assignment
- Initialization
- Comparison
- Field Copying
Union
- Record의 field들은 서로 다른 위치에 저장되었다.
- Union은 field의 크기만큼 최대 메모리에서 할당한다.
- Union을 variant record(가변 레코드)로 보기도 한다.
Design issues
- type checking을 위해
tag를 사용한다.ALGOL 68에서는conformity clauses를 사용했을 때만 reference가 가능하다.Pascal에서는tag값 각각에 대한 assign이 가능하다. 이 때문에 type checking에 문제가 있다.Ada에서는 Constraint variant record, Unconstrained variant record를 모두 지원한다.- Constraint variant record의 경우 variant타입이 바뀔 수 없다.
- Unconstraint variant record의 경우 Pascal처럼 variant타입이 바뀔 수 있다.
- Union을 Record의 일종으로 보아야 하는지 고려해야 한다.
Pointer
C에서 처음 포인터 개념을 도입하기 전에도Pascal,ALGOL에서 포인터 개념은 사용되었다.- 포인터는 addressing의 flexibility를 증가시키기 위해 사용되며, 동적 메모리 관리를 담당한다.
- function allocation을 포인터를 사용해서 하기도 한다.
Design Issues
- 포인터 변수의 lifetime
- 동적 할당된 변수의 lifetime
- 명시적 포인터(
C,C++), 암시적 포인터(Java,C++)
Pointer Operations
- address-of opertaion
- assginment(assignment of an address)
- dereferencing
포인터의 문제점
- Dangling Pointers
- 허상 포인터
- 존재 자체로 문제이며 위험하다.
- 메모리 해제 과정의 문제로 발생한다. 이 떄문에 delete가 없는
java에서는 문제가 되지 않는다.
- Lost Heap Dynamic variable
- 분실 객체
- garbage라고도 한다.
- 크게 위험하다기 보다는 메모리 낭비의 원인이 된다.
Dangling Pointer 문제 해결
- Tombstone 사용
- 포인터가 메모리를 해제하면 Tombstone(비석)이 이 메모리는 죽었다고 표시하여 다른 포인터가 참조하지 못하도록 한다.
- Locks-and-Keys
- 모든 포인터는 ordered pair로 존재한다(key, address)
- key값이 0이면 invalid이다.
- 두 방법 모두 검사가 필요하므로 성능 면에서 비효율적이다.