Written by JS970
on
on
Virtual Memory Management Strategy(2)
Thrashing
- 프로세스에 충분한
page frame이 할당되지 않으면page fault rate가 높아지게 된다. page fault가 발생하게 되면 새로운 페이지를 로드하기 위해 기존의 프레임을 backing store에swap out해야 한다.- 하지만 다시 이 데이터를 필요로 할 경우 또
swapping이 일어나게 된다. - 이러한 악순환은 CPU utilization을 낮추게 된다. 이에 운영체제는 multiprogramming의 강도를 높여 CPU utilization을 높이려고 시도한다.
- 하지만 이는 한계가 있다.
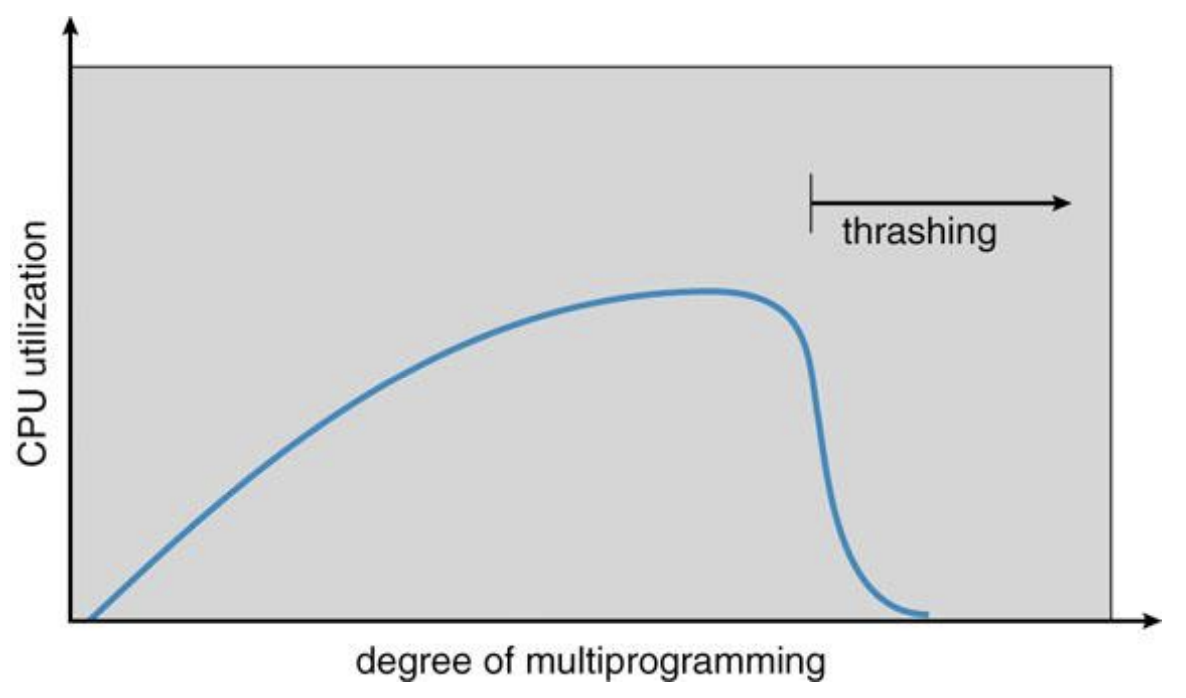
- 과도한 multiprogramming으로 인해
swapping의 빈도가 오히려 늘어나게 되면서 어떠한 프로세스의page fault가 급격하게 증가하여 오히려 성능을 하락시크는 요인이 된다. - 이를
Thrashing이라고 한다.
- 과도한 multiprogramming으로 인해
Thrashing 방지
Thrashing이 일어나는 것을 방지하기 위해서 프로세스는 충분한page frame을 확보해야 한다.- 이때 "충분" 하다는 것은 어떻게 알 수 있을까?
- 프로세스 실행의
Locality model을 사용한다.
Locality란 함께 실행되는pages의 집합을 의미한다.- 함수 호출을 생각하면 된다.
- 프로세스는
locality에서locality로 이동한다고 생각할 수 있다. - 즉, 어떤 시점에 필요한 page는
locality를 가진다. - 또한
locality는 중복될 수도 있다.
Thrashing이 일어나는 궁극적인 원인은 다음과 같이 정리할 수 있다.- The size of the current locality > The size of allocated frame
Working Set
Working-Set이란locality에 기반한Thrashing해결 모델이다. $$\Delta \equiv the\ working\ set\ window$$- 단위 시간 당
page의 참조 횟수를 의미한다. $$WS_i \equiv the\ working\ set\ of\ Process\ P_i$$ - 프로세스 Pi의
working Set을 의미한다. - 이는 시간에 따라 변할 수 있다.
working set은 interval timer와 reference bit을 이용하여 측정한다.- interval timer의 interrupt마다 reference bit을 set한다.
- 만약 reference bit을 확인했을 때 1로 set되어 있다면
working set으로 간주한다. $$WSS_i\equiv the\ size\ of\ WS_i$$ - WSi의 크기를 의미한다.
- 만약 델타 값이 너무 작다면 WSSi는
locality를 반영할 수 없을 것이다. - 만약 델타 값이 너무 크다면 몇 개의
locality를 합친 상태로 표현할 것이다. - 만댝 델타 값이 무한대라면 전체 프로그램을 포함해 버릴 것이다.
- WSi값이 시간에 따라 변할 수 있으므로 WSSi값 역시 변할 수 있다. $$D\equiv the\ total\ demand\ for\ frames = \sum WSS_i$$
- D값은 프로세스가 요구하는
page frame의 개수를 의미한다.
- 단위 시간 당
- 만약 D > m(Number of frame available)이라면
Thrashing이 발생하게 된다.- 이때, 프로세스를 suspend하여
Thrashing을 막아야 한다.
- 이때, 프로세스를 suspend하여
- 일반적으로
working set에서의page fault rate가 아래와 같은 비율로 측정되면working set이 적절히 설정되었다고 본다.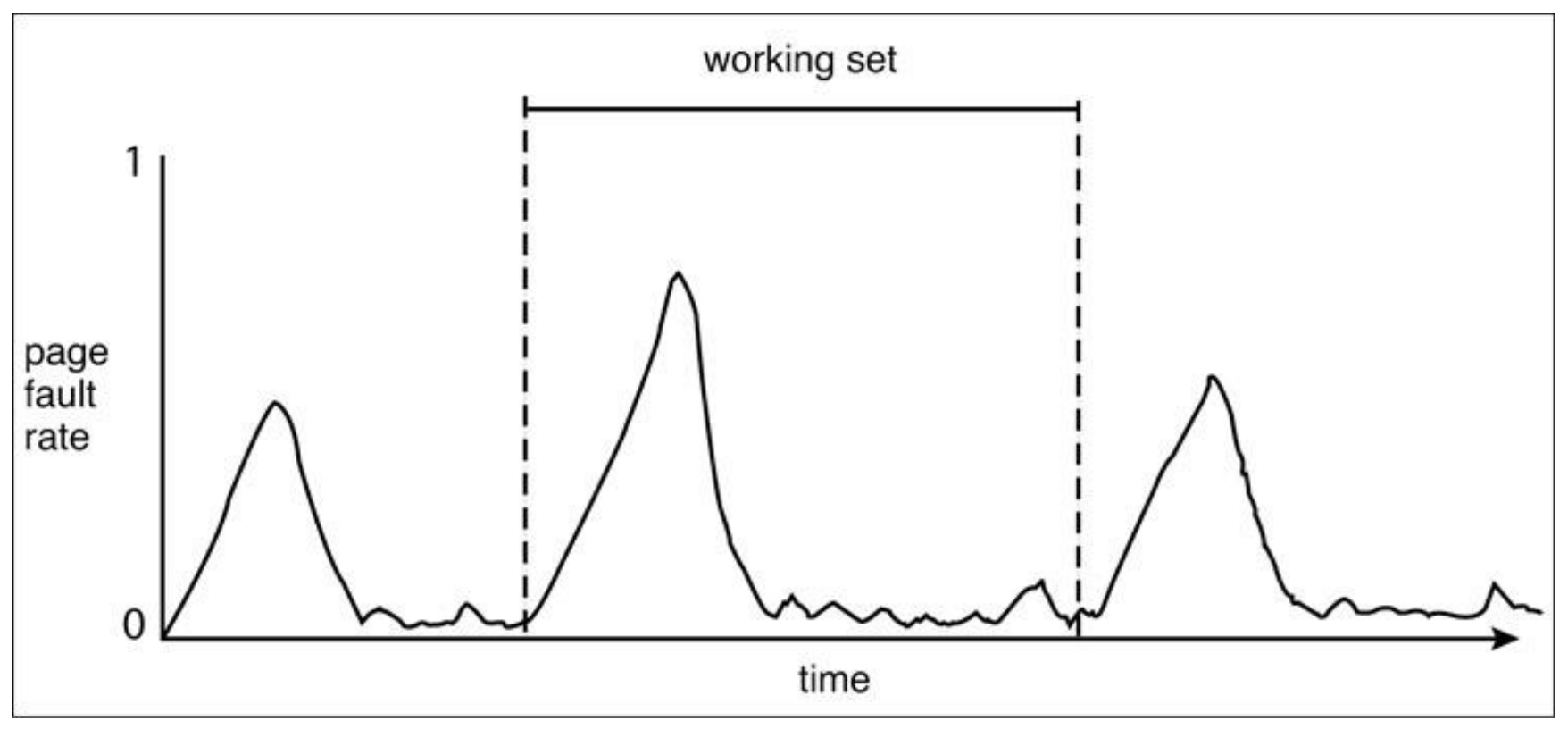
- 2% 정도의 구간에서 빈번하게
page fault가 발생한다. 이를 완전히 없에는 것은 불가능하다. - 98% 정도의 구간에서 높지 않은 비율로
page fault가 발생한다.
- 2% 정도의 구간에서 빈번하게
PFF(page-fault frequency)
Working-Set방법보다 훨씬 직관적인 방법이다.page fault가 일어나는 비율을 측정하여 이 정도에 따라 프레임 개수를 조절한다.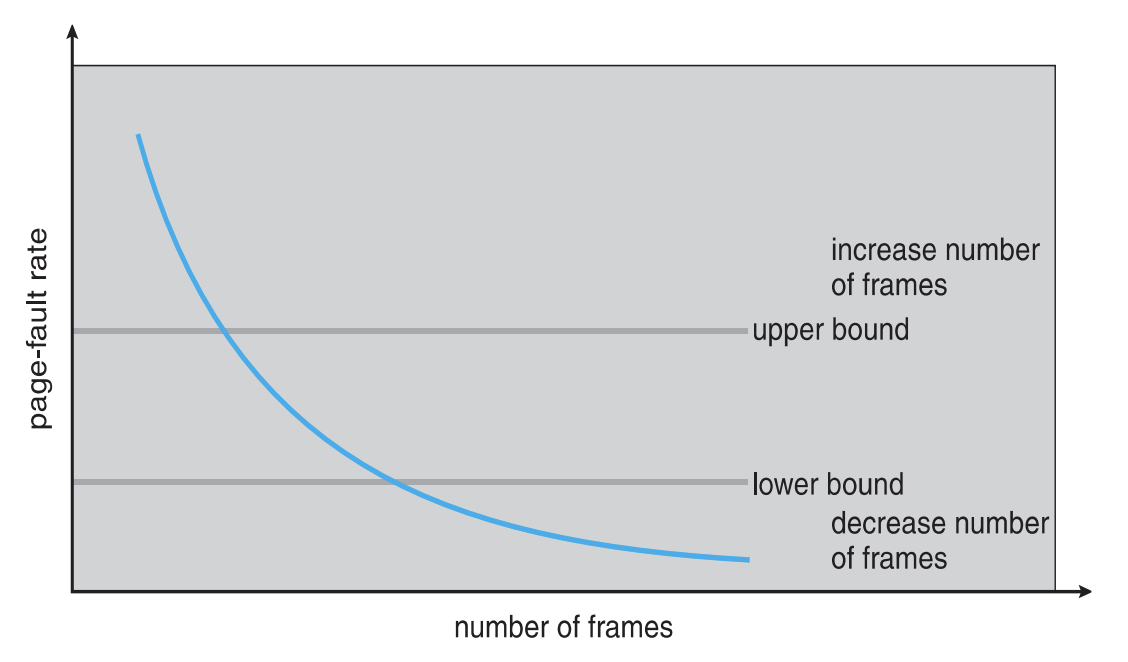
- upper bound 이상으로
page fault가 발생하면 프로세스에 할당하는page frame의 개수를 늘린다. - lower bound 이하로
page fault가 발생하면 프로세스에 할당하는page frame의 개수를 줄인다. - 중간 값일 경우 현 상황을 유지한다.
- upper bound 이상으로
Memory-Mapped Files
- disk file을
physical memory에 1 : 1매핑하여 사용한다. - 이를
MMIO(Memory Mapped IO)라고 한다. 당연히 일반 disk file의 로딩 속도보다 훨씬 빠르다.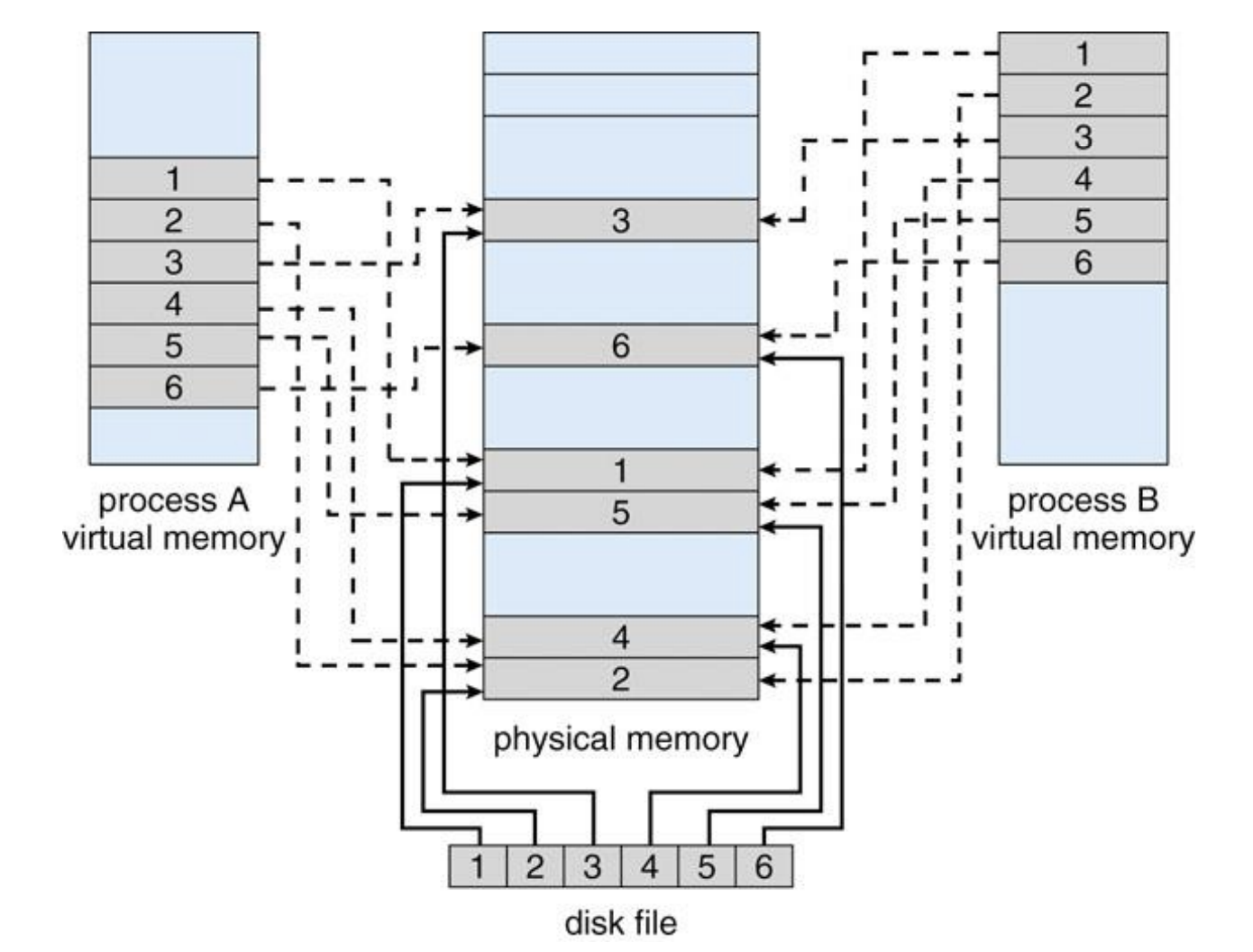
Kernel Memory Allocation
- Kernel memory allocation은 앞서 살펴본 user memory allocation과는 차이가 있다.
- kernel은 다양한 크기의 자료 구조에 대한 메모리를 요청한다.
- 어떤 kernel메모리는 contiguous allocation을 요구한다.
- Buddy System과 Slab allocation이 일반적인 구조로 알려져 있다.
Buddy System
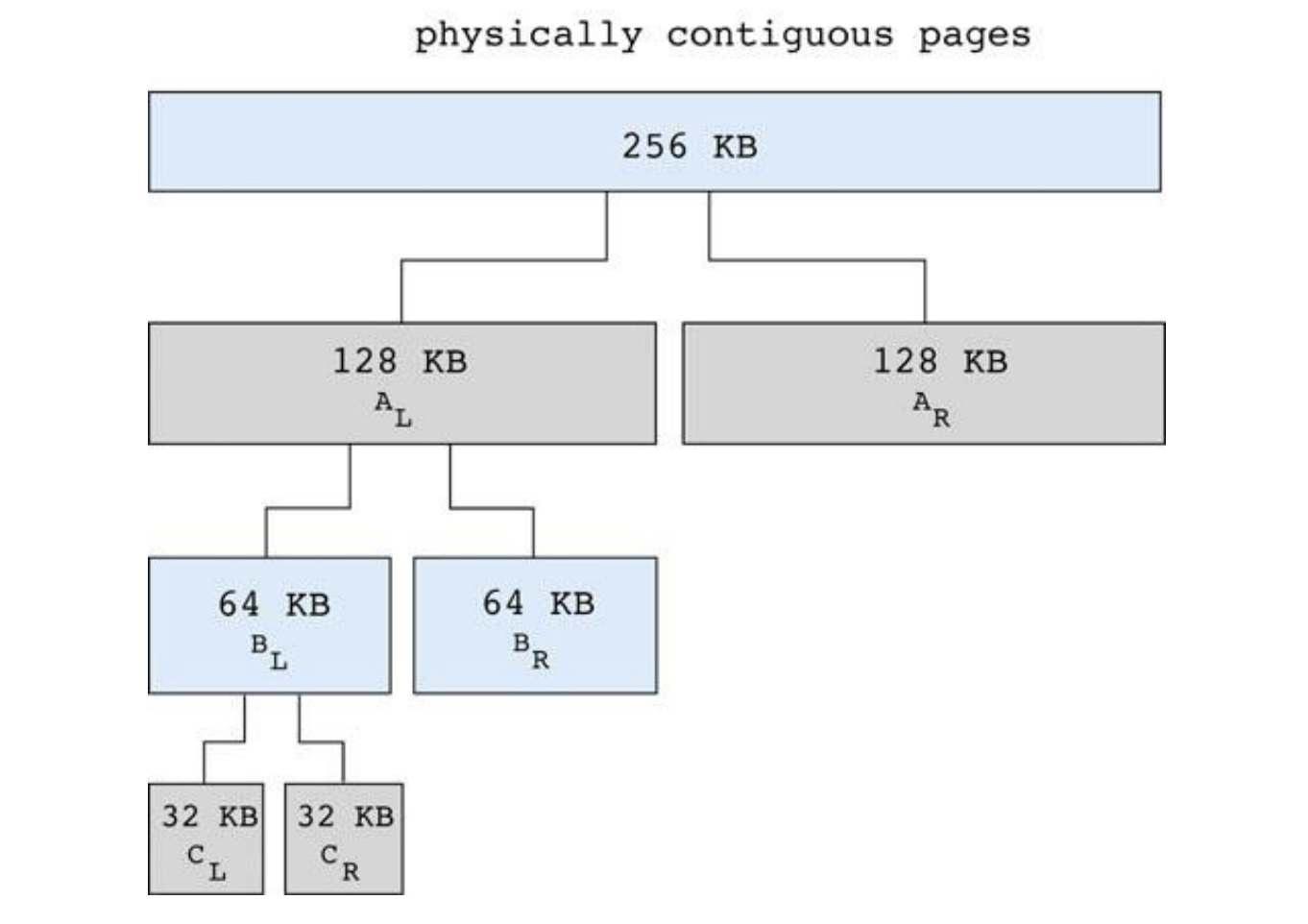
- 물리적으로 연속된 메모리 할당을 한다.
- 2의 거듭제곱 크기의 메모리를 할당한다.
- 만약 33크기의 메모리 할당이 필요하다면 실제로는 64크기가 할당된다.
Slab allocation
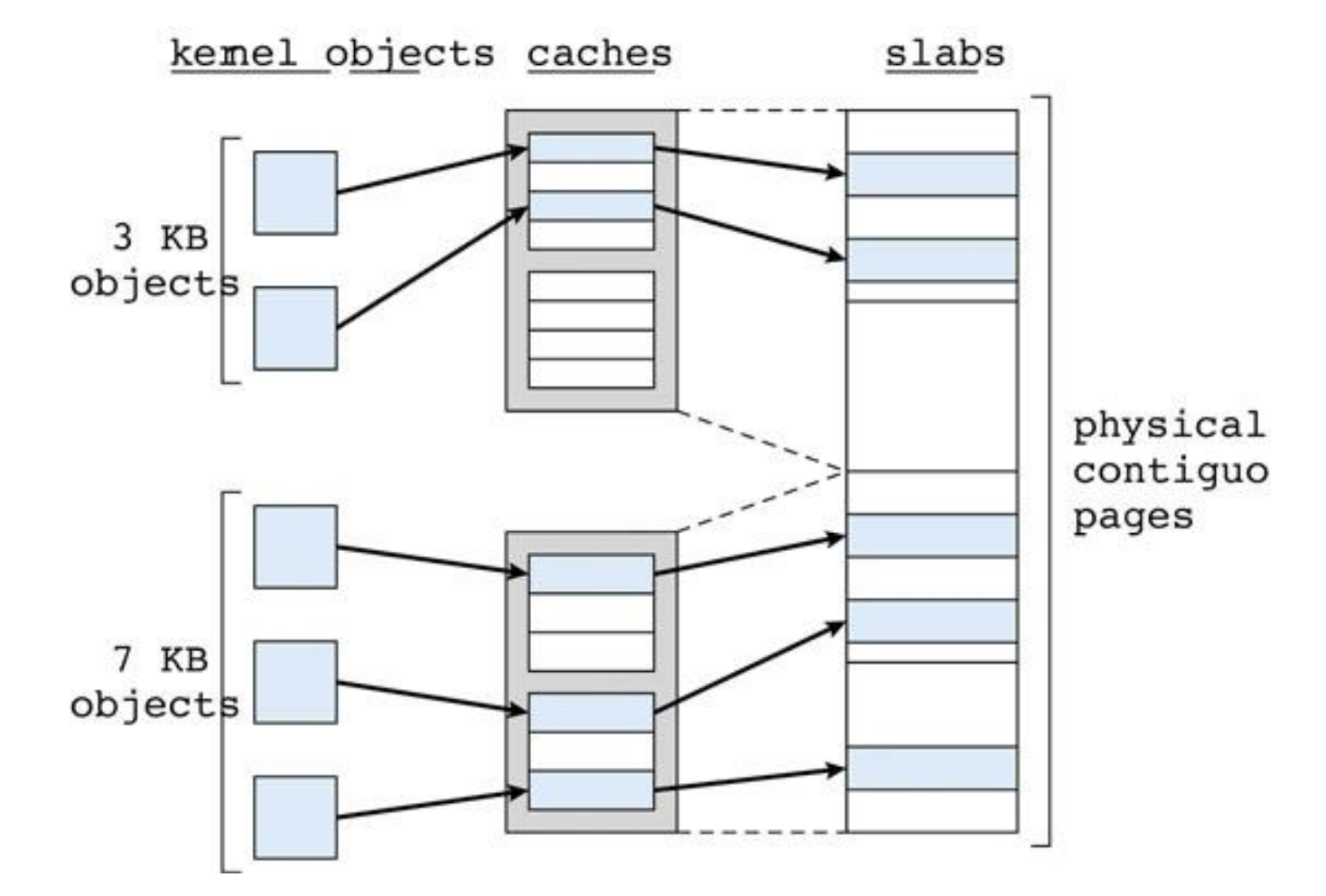
- user memory allocation의 heirarchical memory allocation과 유사하다.
cache가slab을 가리키는 형태이다.
Other Issues
page size에 따른 관점들, 정답은 없다. 상황에 따라 적절한 지점을 찾아야 한다.- Fragmentation :
page크기가 작을 수록 internal fragmentation이 적을 것이다. - Table size :
page table의 크기를 작게 유지하기 위해서는 상대적으로 큰page를 가져야 한다. - I/O Overhead :
page가 클수록 지연시간이 길어진다. - Locality :
page가 작을수록 locality측면에서 좋다.
- Fragmentation :
TLB- 용량이 클수록 비싸진다.
page size가 클수록 fragmentation문제가 많이 발생한다.- 여러 개의
page size를 관리하기 위해서는 OS가TLB까지 관리해야 한다.- 이 결과 OS의 관리 범위가 늘어난다.